 Say we are doing some data analysis. And our project directory has two folders that contains code and inputs: code and data.
Say we are doing some data analysis. And our project directory has two folders that contains code and inputs: code and data.
We want to read data from the data folder, run code from the code folder, and output our analysis results with plots in .png and analysis in .txt files.
| Name | In/Out |
|---|---|
| code | the file |
| data | input |
| images | output |
| analysis | output |
Mastering paths allows us to make our code portable and less error prone.
What portable means that whoever receives our code and files can run it on their computer without running into errors. They do not have to update folder path names in the code.
1. Create directory
When we run a lot of analysis, we can automate creating the directories. os.path.exists returns True/False given whether the folder in question exists or not. os.path.exists goes ahead with making the folder if it is not there.
In [1]: import os
...: os.mkdir('demo')
...: folder_list=['code','data','images','analysis']
...: def makedir(folder):
...: if not os.path.exists(folder):
...: os.mkdir(folder)
...: for folder in folder_list:
...: makedir('demo/'+folder)
...: os.listdir('demo/')
...:
Out[1]: ['analysis', 'code', 'data', 'images']
If we happen to have an old folder with the same name, we need to remove it first. Otherwise the above will run into errors.
import shutil
shutil.rmtree('demo', ignore_errors=True)
2. Access directory, content and change directory
When we need to know where we are, use os.getcwd(). To change that, use os.chdir() with full path as the parameter or use “./” with relative path.
os.path.getsize gives the size of a file (not folder).
In [2]: os.getcwd()
Out[2]: 'C:\\Users\\sache'
In [3]: os.chdir('demo')
In [4]: os.getcwd()
Out[4]: 'C:\\Users\\sache\\demo'
In [5]: os.listdir()
Out[5]: ['analysis', 'code', 'data', 'images']
3. Move files to where we want
Now we have set up the folder structure, we need to get the input files, some of which may come from another folder. os.getcwd(). To change that, use os.chdir() with full path as the parameter or use “./” with relative path.
os.path.getsize gives the size of foler. Because we just created the folder, it has size 0.
In [9]: import os, shutil, pathlib, fnmatch^M
...: ^M
...: def move_dir(src: str, dst: str, pattern: str = '*'):^M
...: if not os.path.isdir(dst):^M
...: pathlib.Path(dst).mkdir(parents=True, exist_ok=True)^M
...: for f in fnmatch.filter(os.listdir(src), pattern):^M
...: shutil.move(os.path.join(src, f), os.path.join(dst, f))^M
...: source =r"C:\Users\sache\OneDrive\Documents\python_SAS\BasicStats\data\for demo"^M
...: destination = 'C:\\Users\\sache\\demo\\data'^M
...: move_dir(source, destination, Pattern='.csv')^M
In [16]: os.listdir('./data')
Out[16]: ['df4.csv', 'df5.csv', 'Iris.csv']
In [19]: os.path.getsize('./data/Iris.csv')
Out[19]: 3867
The following snippet of summing file sizes in folder is from stackoverflow
In [20]: def get_size(start_path = '.'):
...: total_size = 0
...: for dirpath, dirnames, filenames in os.walk(start_path):
...: for f in filenames:
...: fp = os.path.join(dirpath, f)
...: # skip if it is symbolic link
...: if not os.path.islink(fp):
...: total_size += os.path.getsize(fp)
...:
...: return total_size
...:
...: print(get_size(), 'bytes')
...:
5655 bytes
4. Write some data analysis program to run
We write two simple scripts for demo.
-
basic_stats.py: it defines a DataDescription class that has two methods: summary statistics for all the columns, and Pearson correlation for the numeric columns.
-
iris_analysis.py: it imports the data from the data folder, and performs the analysis using basic_stats. This is the program we call on the command line.
Notice that in these two programs, we have not coded any full path name. That’s because the full path name was given in __file__.
import os
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
class DataDescription(object):
def __init__(self, data,cate):
self.data = data
self.cate = cate
def summary(self):
summary = self.data.groupby(self.cate).describe().unstack().unstack().round(2)
print(summary)
return summary
def cal_corr(self):
pearson_corr = self.data.groupby(self.cate).corr(method='pearson').round(2)
# spearman_corr = self.data.groupby(self.cate).corr(method='spearman').round(2)
print("\n PEARSON",pearson_corr)
# print("\n SPEARMAN",spearman_corr)
return pearson_corr
import os
import pandas as pd
import warnings
from basic_stats import DataDescription
warnings.filterwarnings('ignore')
base_path = os.path.abspath(os.path.join(__file__, "../.."))
input_path = os.path.join(base_path,'data')
output_path = os.path.join(base_path,'analysis')
print("\n input_path",input_path)
df = pd.read_csv(os.path.join(input_path,"Iris.csv"))
print(df.shape)
print(df.info())
summary = DataDescription(df,'species').summary()
corr = DataDescription(df,'species').cal_corr()
corr.to_excel(os.path.join(output_path,'iris_corr.xlsx'))
summary.to_excel(os.path.join(output_path,'iris_summary.xlsx'))
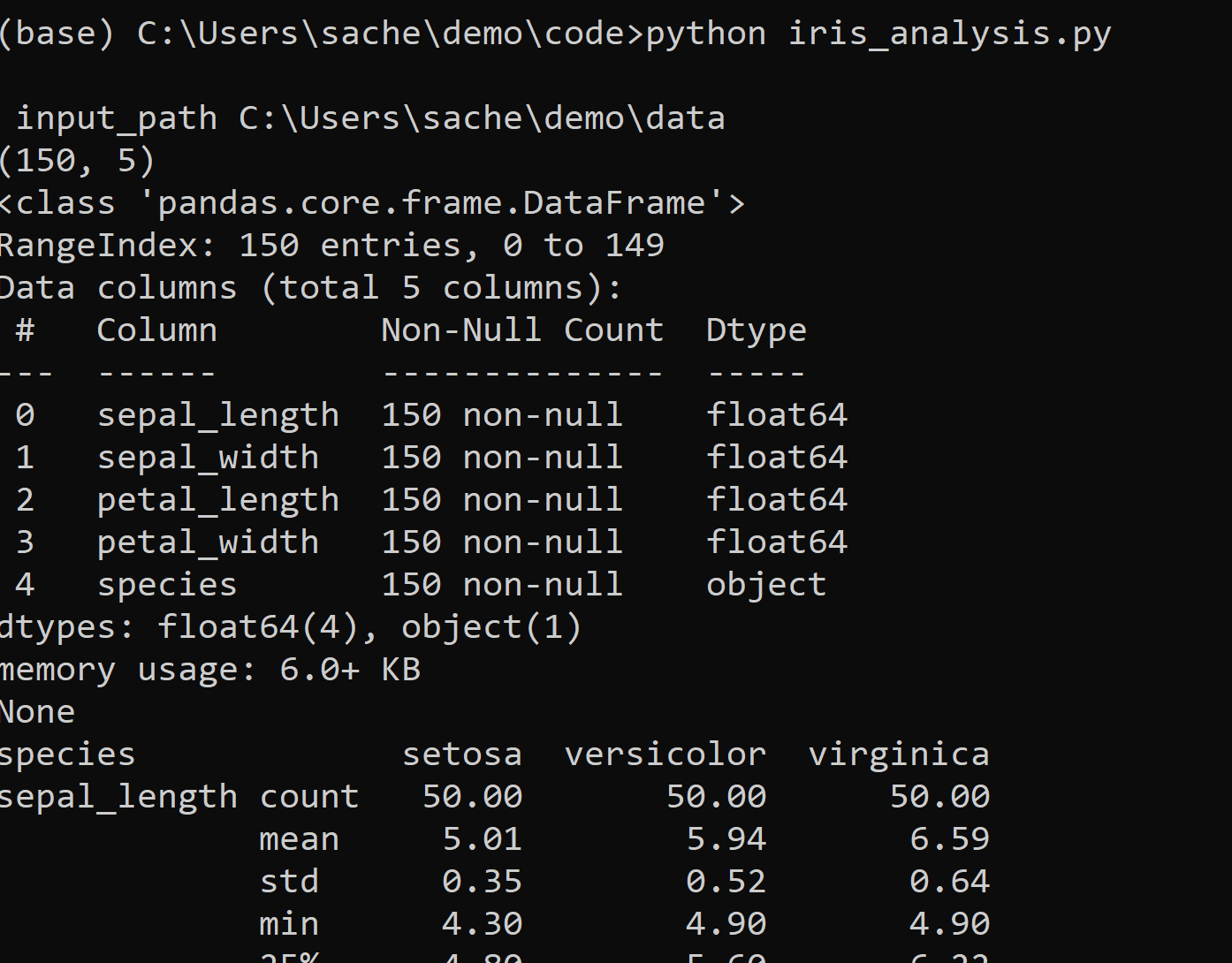
Some of the result of running the program is in the screenshot below.
”\” or “/”
On Windows, paths are written using backslashes (\, the key with “|”) as the separator between folder names.
OS X and Linux, however, use the forward slash (/, the key with “?”) as their path separator.
path=os.path.join(dir,subdir,filename) is easier than path=dir + ‘/’ + subdir + ‘/’+filename`, although they equivalent. path=os.path.join(dir,subdir,filename) is better than string concatenation because it prevents cross-platform issues.
Solution 1. Double \\
Two wrongs make it right. Just double it up.
Solution 2. Add ‘r’
Ask Python to do the job and read it.
Solution 3. os.path.join()
Use it with (full path name minus relative directory).
With some extra typing, the os.path.join() function helps solving this problem. os.path.join() glues the path pieces together using the correct path separators.
>>> df = pd.read_csv("C:\Users\sache\OneDrive\Documents\python_SAS\df4.csv")
File "<ipython-input-8-24f5fb082f1d>", line 2
df = pd.read_csv("C:\Users\sache\OneDrive\Documents\python_SAS\df4.csv")
^
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: truncated \UXXXXXXXX escape
# Solution 1. Double \\
>>> df = pd.read_csv(r"C:\Users\sache\OneDrive\Documents\python_SAS\data\df4.csv")
# Solution 2. Add 'r'
>>> df = pd.read_csv("C:\\Users\\sache\\OneDrive\\Documents\\python_SAS\\data\\df4.csv")
# Solution 3. os.path.join
>>> df = pd.read_csv(os.path.join('.','OneDrive\Documents\python_SAS\data\df4.csv'))
Absolute path
| function, notation | usage |
|---|---|
| os.path.abspath | Asolute path is the full path from the address bar |
| os.path.relpath | Relative path gives the difference between two input paths |
| os.path.abspath(‘.’) | equivalent to os.getcwd() |
| . | denotes current working directory |
| .. | denotes backward a step, i.e.subtract a step in path |
In [1]: import os
os.path.abspath('.')
Out[1]: 'C:\\Users\\sache'
In [2]: os.path.abspath('.\\onedrive')
Out[2]: 'C:\\Users\\sache\\onedrive'
In [3]: os.path.isabs(os.path.abspath('.'))
Out[3]: True
In [4]: os.path.relpath('C:\\Windows', 'C:\\')
Out[4]: 'Windows'
In [5]: os.path.relpath('C:\\Windows', 'C:\\windows')
Out[5]: '.'
In [6]: os.path.relpath('C:\Windows', 'C:\windows')
Out[6]: '.'
In [7]: os.path.relpath('C:/Windows', 'C:/windows')
Out[7]: '.'
In [1]: import os
os.path.abspath('.')
Out[1]: 'C:\\Users\\sache'
In [2]: os.path.abspath('.\\onedrive')
Out[2]: 'C:\\Users\\sache\\onedrive'
In [3]: os.path.isabs(os.path.abspath('.'))
Out[3]: True
In [4]: os.path.relpath('C:\\Windows', 'C:\\')
Out[4]: 'Windows'
In [5]: os.path.relpath('C:\\Windows', 'C:\\windows')
Out[5]: '.'
In [6]: os.path.relpath('C:\Windows', 'C:\windows')
Out[6]: '.'
In [7]: os.path.relpath('C:/Windows', 'C:/windows')
Out[7]: '.'
Partitioning a path
folder name and file name
We can partition a full path name into parent and child: os.path.==dirname==(path), the parent directory: before the last slash in the path argument.
os.path.==basename==(path)</sapn>, the child: after the last slash in the path argument.
When a script is executed through the commandline, __file__’ refers to the script file that is being run. os.path.abspath(__file__) gives the complete path, which means the folder path + the file name.
In this case, the parent is the folder path, while the child is the file name.
import os
ABS_PATH = os.path.abspath(__file__)
print("\n ABS_PATH ", ABS_PATH)
PARENT_PATH = os.path.dirname(ABS_PATH)
print("\n PARENT_PATH ",PARENT_PATH)
CHILD_PATH = os.path.basename(ABS_PATH)
print("\n CHILD_PATH ",CHILD_PATH)
# The result of running the above code is as followed:
#(base) C:\Users\sache\OneDrive\Documents\python_SAS\Code_only>python learn_path2.py
# ABS_PATH C:\Users\sache\OneDrive\Documents\python_SAS\Code_only\learn_path2.py
# PARENT_PATH C:\Users\sache\OneDrive\Documents\python_SAS\Code_only
# CHILD_PATH learn_path2.py
split folder path
{In [28]: path
Out[28]: 'C:\\Users\\sache\\OneDrive'
In [29]: os.path.split(path)
Out[29]: ('C:\\Users\\sache', 'OneDrive')}
Grandparent and great grandparents
Using the same logic of getting the parent, we can access the grandparent directory using os.path.dirname repeatedly.
A better way to do this is os.path.abspath(os.path.join(path,”../../..”)).
Note that os.path.join(path, “../../..”) just glues the steps together. It does not know “../../..” is to go back 2 steps. os.path.abspath applies the step calculations.
In [19]: os.getcwd()
Out[19]: 'C:\\Users\\sache\\OneDrive'
In [21]: os.path.dirname(path)
Out[21]: 'C:\\Users\\sache'
In [23]: os.path.dirname(os.path.dirname(path))
Out[23]: 'C:\\Users'
# alternatively
In [33]: os.path.abspath(os.path.join(path,"../../.."))
Out[33]: 'C:\\'
Relative path and absolute path
import os
PROJECT_ROOT = os.path.dirname(os.path.abspath(__file__))
print("PROJECT_ROOT is ",PROJECT_ROOT)
BASE_DIR = os.path.dirname(PROJECT_ROOT)
print("BASE_DIR is",BASE_DIR)
# PROJECT_ROOT is C:\python_SAS\Code_only
# BASE_DIR is C:\python_SAS
The os.path.dirname() function removes the last segment of a path. file is the pathname of the file from which the module was loaded, if it was loaded from a file.
import os
PROJECT_ROOT = os.path.dirname(os.path.abspath(__file__))
print("PROJECT_ROOT is ",PROJECT_ROOT)
BASE_DIR = os.path.dirname(PROJECT_ROOT)
print("BASE_DIR is",BASE_DIR)
# PROJECT_ROOT is C:\python_SAS\Code_only
# BASE_DIR is C:\python_SAS
Now, open the command prompt, or Anaconda Prompt, type “python learn_path.py”, as shown below, we will get the output as expected. Both the first and the second function ran. The second function ran because the name of the module according to the Python interpreter, is __name__ == ‘__main__’.
On the other hand, if a module is not the main program but is imported by another one, then __name__ attribute will be the name of the scirpt, in this case it is “learn_main”, not __main__. Since the __name__ is not __main__, then whatever __main__ does will be ignored.
This neat trick helps us reuse code more flexibly.
SAS
In aside from the command line, elsewhere we need to tell SAS what directory we want as the base path.
%let rundir = C:/Users/sache/onedrive/;
%include "&rundir/../codeonly/path.sas";
Relative file paths in SAS are relative to the ‘current directory’. If you want a path that is relative to the path of the current program, you have to build it yourself. To get the path of the current program, use SYSGET(“SAS_EXECFILEPATH”) in a data step or %qsysfunc(sysget(SAS_EXECFILEPATH)) in macro code.