Hash tables can be seen as indexed arrays via hash functions. Hash tables are slightly fancier version of arrays.
hash table the basics
A hash table is a data structure that is like a Python dictionary. It is designed to store keys (and optionally) with associated values in an array.
A key is stored in the array locations based on its hash code, which is an integer \(\text{hash code}=\text{array index}=f(\text{input key})\).
Hash function maps keys to array indices.
Hash codes or hash values are integers that are array indices that are used during a dictionary lookup quickly.
Compare with binary search trees (BSTs), hash tables are more efficient in access (find), insert and delete, as long as we have a good hash function.
- Time complexity: find, insert, and delete all in \(O(1)\) time if we have a good hash function.
hash function
A good hash function distributes hash codes uniformly through the array locations, which prevents collision as much as possible and promotes super fast access, insertion and deletion.
- Hash keys must be unique.
- But different keys can map to the same value (think frequency tables: different things can have the same count)
one-to-one or many-to-one
Same keys must map to the same hash code. Although not in any way related, but same keys to a lock should both open it, right?
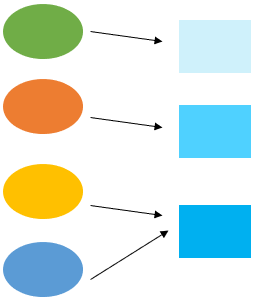
Hash functions are one-to-one or many-to-one. It can never ben one to many!
\(\text{If}x=y \text{then} f(x)=f(y)\) \(\text{Converse is not true}\)
In other words \(f(x)=f(y)\) then \(x \text{ may or may not}=y\)
Usage: If we have already computed the hash, then it suffices to compare the hashed instead of the originals.
- Compare hashed \(f(x)\) and \(f(x)\); if not equal, then \(x\) and \(y\) are definitely not equal
- If the hashed are equal, then we have to compare \(x\) and \(y\) bit by bit to see if they are indeed equal or due to collision
Deterministic
Hash function (input and output) must be constant (stay the same). It would have been a disaster if it changes during use.
hashable
Hashable means if an object can be hashed (circular definition): those that satisfy the deterministic requirement: the immutable ones. Immutable means not likely to be changed. Therefore, many programming languages require hash keys be immutable.
Internally, hash() method calls hash() method of an object which are set by default for any object.
Table below summarizes mutual and immutable objects in Python:
| Immutable | Mutable |
|---|---|
| int, float, decimal, complex, bool, string, tuple, range, frozen set, bytes | list, dict, set, bytearray, user-defined classes |
keys can be strings or integers, which are immutable.
An error that I have made in the past is the following. I used a list as a key in the code below and got a TypeError.
graphDict[someList]
# TypeError: unhashable type: 'list'
Hash tables in Python
Python has 4 built-in hash table types: set, dict, collections.defaultdict, collections.Counter, where a set only stores keys.
The pandas DataFrame class can be thought of as a dict-like container for Series objects.
defaultdict
collections.defaultdict is nothing but a dict with an added option to specify default, so that error can be prevented if key is not found.
Counter
The Counter class creates a frequency table associated with the input.
c = Counter() # a new, empty counter
c = Counter('hello') # a new counter from an iterable such as string or list
print(c)
# Counter({'l': 2, 'h': 1, 'e': 1, 'o': 1})
c = Counter({'high': 100, 'low': 5000}) # a new counter from a mapping
# Counter({'low': 5000, 'high': 100})
c = Counter(high=100, low=5000) # a new counter from keyword args
You can skip using pandas df.value_counts() next time you need a frequency count. In addition to frequency count, you can also use most_common() to get the most frequent ones.
df = sns.load_dataset('iris')
df.species.value_counts()
# setosa 50
# versicolor 50
# virginica 50
# Name: species, dtype: int64
df.species.value_counts().nlargest(1)
# setosa 50
# Name: species, dtype: int64
Counter(df.species)
# Counter({'setosa': 50, 'versicolor': 50, 'virginica': 50})
Counter(df.species).most_common(1)
# [('setosa', 50)]
set
sets are my favorite objects. I use sets whenever I can when comparing memberships.
Hash table examples
Find anagram
In Python, a string is a sequence (list) of unicode. So when we apply the sorted method, the letters become separated individuals sorted in a sequence.
The sorted sequence of the letters are joined without space. It becomes the representative of its anagram group.
This reminds me of class representatives in math.
A set of class representatives is a subset of X which contains exactly one element from each equivalence class.
For example, prime number factorizaiton equivalence class is a kind of equivalence class.
Here we use defaultdict as the hashtable.
from collections import defaultdict
def find_anagram(wordList):
dd = defaultdict(list)
for word in wordList:
print(word, sorted(word))
dd[''.join(sorted(word))].append(word)
return dd
words = ['debitcard','badcredit', 'below', 'taste','state','elbow', 'listen','levis', 'elvis', 'lives','freedom']
d = find_anagram(words)
for k, w in d.items():
if len(w) > 1:
print('equivalent to: {}, {}'.format(k, w))
# Out:
# debitcard ['a', 'b', 'c', 'd', 'd', 'e', 'i', 'r', 't']
# badcredit ['a', 'b', 'c', 'd', 'd', 'e', 'i', 'r', 't']
# below ['b', 'e', 'l', 'o', 'w']
# taste ['a', 'e', 's', 't', 't']
# state ['a', 'e', 's', 't', 't']
# elbow ['b', 'e', 'l', 'o', 'w']
# listen ['e', 'i', 'l', 'n', 's', 't']
# levis ['e', 'i', 'l', 's', 'v']
# elvis ['e', 'i', 'l', 's', 'v']
# lives ['e', 'i', 'l', 's', 'v']
# freedom ['d', 'e', 'e', 'f', 'm', 'o', 'r']
# equivalent to: abcddeirt, ['debitcard', 'badcredit']
# equivalent to: below, ['below', 'elbow']
# equivalent to: aestt, ['taste', 'state']
# equivalent to: eilnst, ['listen']
# equivalent to: eilsv, ['levis', 'elvis', 'lives']
If letter can be constructed
Given a letter, and a magazine (or another letter), both contain text.
Problem: can the letter be constructed using the characters in the magazine?
If any charaters are left, then it implicitly implies True. So, adding not returns False, because letter cannot be constructed using the characters in the magazine.
from collections import Counter
def L_subset_of_M(L, M):
result = Counter(L) - Counter(M)
return not result
print(L_subset_of_M("ab","a"))
Time complexity is \(O(l+m)\), where \(l\) is the number of the charaters in letter. Space complexity is \(O(L+M)\), where \(L\) is the number of distinct charaters in letter.
This is not the best solution in terms of cost, but it is the simplest, which can matter more, especially to senior management.
Below method is lower in cost but has longer code.
- In comparison with the above, this one uses hash table only once, and use it on \(L\), the one of interest. freq_L = Counter(L
- Then it iterates through elements of \(M\), if the element is in \(L\), then subtract the frequency count by 1. If the frequency count is 0, then remove this element from the frequency hash table freq_L of . If freq_L has nothing left, then return True, yes, it is constructable from \(M\).
This method still has time complexity of \(O(l+m)\), where \(l\) is the number of the charaters in letter because of consideration of worst case. But Space complexity is \(O(L)\), because we only have 1 hash table.
from collections import Counter
def L_subset_of_M(L, M):
freq_L = Counter(L)
for c in M:
if c in freq_L:
freq_L[c] -=1 # reduce L
if freq_L[c] == 0:
del freq_L[c]
if not freq_L: # L has been exhausted
return True
return not freq_L
print(L_subset_of_M("adefghb","zhighuvdabfea"))