Introduction
Graphs, or networks, are useful for representing relationships. In this post, we learn common problems that are solved using graph theory, and a few of the most well-known algorithms.
Problems
Shortest path problem
Given a weighted graph, find the shorted path from node A to node B with minimal cost (or weight).
For example, Amazon delivery routes where heavy traffic has large weights. And in credit risk rating models: the least (or the most) likely path from rating A to rating B.
Algorithms:
- BFS (unweighted graph)
- DIjkstra’s
- Bellman-Ford
- Floyd-Warshall,
- A*
Negative cycles
Detect existence of negative cycles and location. Negative cycle is like air bubles in a radiator heaters, or blood clots in our bodies, or black markets. Negative cycle forms a cycle within itself.
Negative cycles can mean good things too: a safe shelter in a hurricane, an arbitrage opportunity that take advantage of inconsistencies in markets (e.g. foreign exchange).
Algorithms:
- Bellman-Ford
- Floyd-Warshall
Strongly connected components
Strongly connected components forms a cycle within itself, where every node in a given cycle can reach every other node in the same cycle. They are like silos.
Algorithms:
- Tarjan’s
- Kosaraju’s
Traveling salesman problem (TSP)
Kind of like the 7 bridge problem but with weights (or distances) on the edges. What is the shortest possible route that he visits each city exactly once and returns to the origin city?
The TSP problem has important applications. However it is NP-hard (computationally difficult).
Algorithms:
- Held-Karp
- branch and bound, and many othe approximations
-
Minimum spanning tree (MST)
Minimum spanning tree is a subset of the edges of a connected, edge-weighted graph that connects all the vertices together, without any cycles and with the minimum possible total edge weight. The MST has many applications.
Algorithms:
- Kruskal’s
- Prim’s & Boruvka’s
Max flow (MST)
With an infinite input source, how much “flow” can we push through the network? Suppose the edges are elevators, escalators at in a building. Flow represents the number of people can be moved up or down.
Bridge
A bridge is a single link between connected components (or local networks). Bridges are where the network vulnearabilities or weak points.
Algorithms: DFS
Algorithms
DFS

It is quite instructive to read the pesudo code from Wikipedia and traverse manually to really understand this algorithm.
It goes as deep as possible before bouncing back to span the left sub-tree, and then to the next child of the root node and plunge all the way again, and then bounce back to span the right sub-tree.
procedure DFS(G, v) is
label v as discovered
for all directed edges from v to w that are in G.adjacentEdges(v) do
if node w is not labeled as discovered then
recursively call DFS(G, w)
The DFS algorithm can be written using recursion with only 4 lines of code (excluding the return statement).
Note that if node not in visited is important for undirected graph. Without it, the recursion will never stop.
The discovered in the psudo code is the list visited in the code. We could have used a set for visited, but a set would not show the order of traversal.
graph ={
'A': ['B', 'C'],
'B': ['D', 'E', 'F'],
'C': ['G'],
'D': [],
'E': [],
'F': ['H'],
'G': ['I'],
'H': [],
'G': []
}
# or
graph ={
'A': ['B', 'C'],
'B': ['A', 'D', 'E', 'F'],
'C': ['A', 'G'],
'D': ['B'],
'E': ['B'],
'F': ['B','H'],
'G': ['C', 'I'],
'H': ['E'],
'G': ['C']
}
def dfs(G, startNode,visited):
# initial value
if startNode not in visited:
visited.append(startNode)
# recurse
for node in G[startNode]:
if node not in visited:
dfs(G, node, visited)
return visited
print(dfs(graph, 'A', []))
# ['A', 'B', 'D', 'E', 'F', 'H', 'C', 'G']
The DFS can also be written using iteratively with short length, using psudo code from Wikipedia.
procedure DFS_iterative(G, v) is
let S be a stack
S.push(v)
while S is not empty do
v = S.pop()
if v is not labeled as discovered then
label v as discovered
for all edges from v to w in G.adjacentEdges(v) do
S.push(w) The iterative DFS and the recursive DFS visit the neighbors of each node in the opposite order from each other: the first neighbor of v visited by the recursive variation is the first one in the list of adjacent edges, while in the iterative variation the first visited neighbor is the last one in the list of adjacent edges.
In other words, while both are depth-first, the recursive goes from left to right whereas the iterative goes from right to left.
def dfs_iterative_r_to_l(G, startNode):
# initialize
visited = []
S = list(startNode)
while S:
node = S.pop()
if node not in visited:
visited.append(node)
# for all edges from v to w in G.adjacentEdges(v)
for node in G[node]:
if node not in visited:
S.append(node)
return visited
print(dfs_iterative_r_to_l(graph, 'A'))
# ['A', 'C', 'G', 'B', 'F', 'H', 'E', 'D']
def dfs_iterative_l_to_r(G, startNode):
# initialize
visited = []
S = list(startNode)
while S:
node = S.pop()
if node not in visited:
visited.append(node)
# for all edges from v to w in G.adjacentEdges(v)
S.extend(reversed(G[node]))
return visited
print(dfs_iterative_l_to_r(graph, 'A'))
# ['A', 'B', 'D', 'E', 'F', 'H', 'C', 'G']
DFS edge classfication
From MIT CS course recitation, the edges we traverse as we execute a depth-first search can be classified into four edge types.
During a DFS execution, the classification of edge \((u, v)\) depends on: if we have visited \(v\) before in the DFS and if so, the relationship between \(u\) and \(v\).
- If \(v\) is visited for the first time as we traverse the edge \((u, v)\), then the edge is a tree edge.
- Else, \(v\) has already been visited: (a) If \(v\) is an ancestor of \(u\), then edge \((u, v)\) is a back edge. (b) Else, if \(v\) is a descendant of \(u\), then edge \((u, v)\) is a forward edge. (c) Else, if \(v\) is neither an ancestor or descendant of \(u\), then edge \((u, v)\) is a cross edge.
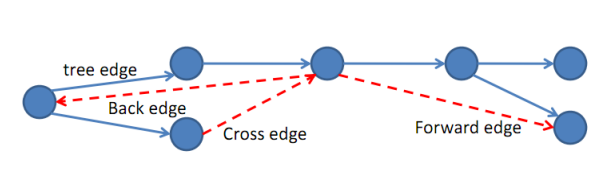
We can use edge type information to learn some things about G. For example, tree edges form trees containing each node DFS visited in \(G\).
\(G\) has a cycle if and only if DFS finds at least one back edge.
DSF can be used for:
- Solving puzzles with only one solution, such as mazes.
- Finding connected components.
- Topological sorting.
- Finding the bridges of a graph.
Topological sort
A topological sort is a graph traversal in which each node is visited only after all its dependencies are visited. This sounds very much like how DFS works.
In DFS, each node at the top is not finished until its dependents are finished.
For every directed edge \((u, v)\) from vertex \(u\) to vertex \(v\), \(u\) comes before \(v\) in the ordering.
The only type of graph that can have topological orderings is DAG. DAGs have no cycles.
The graphlib library, part of Python standard library. Its graphlib.TopologicalSorter does exactly topological sort.
graph = {"D": {"B", "C"}, "C": {"A"}, "B": {"A"}}
ts = TopologicalSorter(graph)
tuple(ts.static_order())
import graphlib
from graphlib import TopologicalSorter
# graph = {"D": {"B", "C"}, "C": {"A"}, "B": {"A"}}
graph ={
'A': ['B', 'C'],
'B': ['D', 'E', 'F'],
'C': ['G'],
'D': [],
'E': [],
'F': ['H'],
'G': ['I'],
'H': [],
'G': []
}
ts = TopologicalSorter(graph)
print(tuple(ts.static_order()))
BFS
A BFS starts at some arbitrary node and explores its neighbors first before moving to the next level of neighbors, in a layer by layer fashion.
BFS is a way to search graph broadly, and useful for finding the shortest path.
BFS uses a queue data structure to track which node to visit next because the traversal is first in and first out (FIFO).
In code below, I use deque in to keep track of the queue. Deques are a generalization of stacks and queues.
From Python documentation: Deques support thread-safe, memory efficient appends and pops from either side of the deque with approximately the same O(1) performance in either direction.
Though list objects support similar operations, they are optimized for fast fixed-length operations and incur \(O(n)\) memory movement costs for pop(0) and insert(0, v) operations which change both the size and position of the underlying data representation.
I could have used extend method instead of a for-loop to append each neighbor one by one because extend is much faster. But there is no method that is the opposite of extend to pop multile items simutaneously. So I stay with the for-loop.
What the bfs function does is to visit nodes layer by layer, and from left to right.
- place starting node to the queue
- while anything is in queue, pop the first item from the queue.
- if what’s popped out has not been visited yet, add it to the
- visited is a set instead of a list.
graph ={
'A': ['B', 'C'],
'B': ['D', 'E', 'F'],
'C': ['G'],
'D': [],
'E': [],
'F': ['H'],
'G': ['I'],
'H': [],
'G': []
}
from collections import deque
def bfs(G, startNode):
# initialize
Q = deque(startNode)
visited = set()
traversal = []
while Q: # do until no more node left
node = Q.popleft()
if node not in visited:
visited.add(node)
traversal.append(node)
Q.extend(G[node])
return traversal
print(bfs(graph, 'A'))
Although the input graph is represented as if it is a directed graph, the BFS works fine if just as well.
graph ={
'A': ['B', 'C'],
'B': ['A', 'D', 'E', 'F'],
'C': ['A', 'G'],
'D': ['B'],
'E': ['B'],
'F': ['B','H'],
'G': ['C', 'I'],
'H': ['E'],
'G': ['C']
}
The negative side is that we have to do more membership tests. For example, when we are at the \(B\) node, we have to ask if \(A\) was in the visited even though we just came from A.
Compare iterative DFS and BFS
The non-recursive implementation is similar to breadth-first search but differs from it in two ways:
it uses a stack instead of a queue, and it delays checking whether a node has been discovered until the node is popped from the stack rather than making this check before adding the node. If G is a tree, replacing the queue of the breadth-first search algorithm with a stack will yield a depth-first search algorithm. For general graphs, replacing the stack of the iterative depth-first search implementation with a queue would also produce a breadth-first search algorithm, although a somewhat nonstandard one.[7]