- Problem
- Topological sort
- DFS vs. Khan’s for topological sort
- Cycle detection
- Compare with Floyd’s algorithm for topological sort
- Appendix
- Know your library
- Reference
Problem
Given a directed hierchical structure, how do we flatten it to an array so that the directions are preserved?
Recall my problem of trying to fly to Beijing, China, while Zero-Covid policy is going on in China, say I have combed through many many flights (edges) and stops (nodes) and have come up with the following possible path.
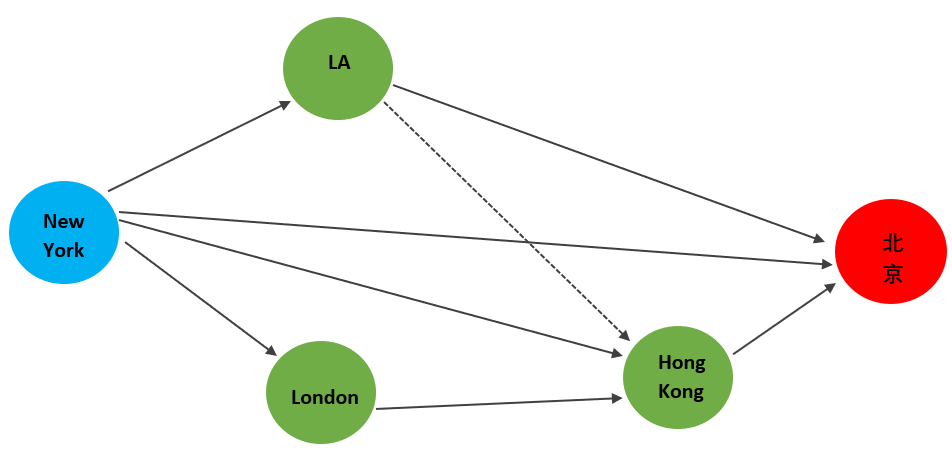
How do I write down each of the valid routes in their right order with sentences?
If we start the routes with “New York -> Beijing”, that will not work for sure. Because we left out other cities.
We can write down my starting place first, since I cannot go anywhere without a starting place. Then we look at where the directed edges lead to, if any of them do not have any dependencies, then we can write it down next. And so forth until we are done.
Topological sort

In a topological sort, the parent needs to come before its children.
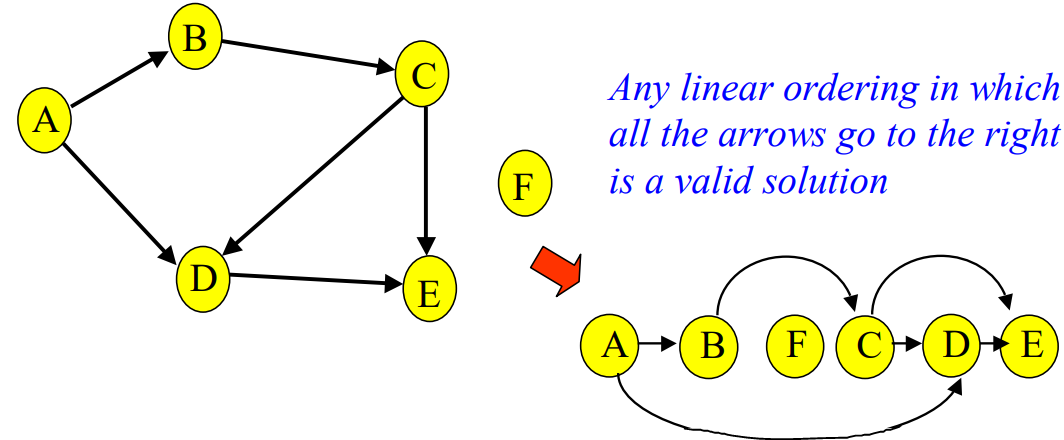
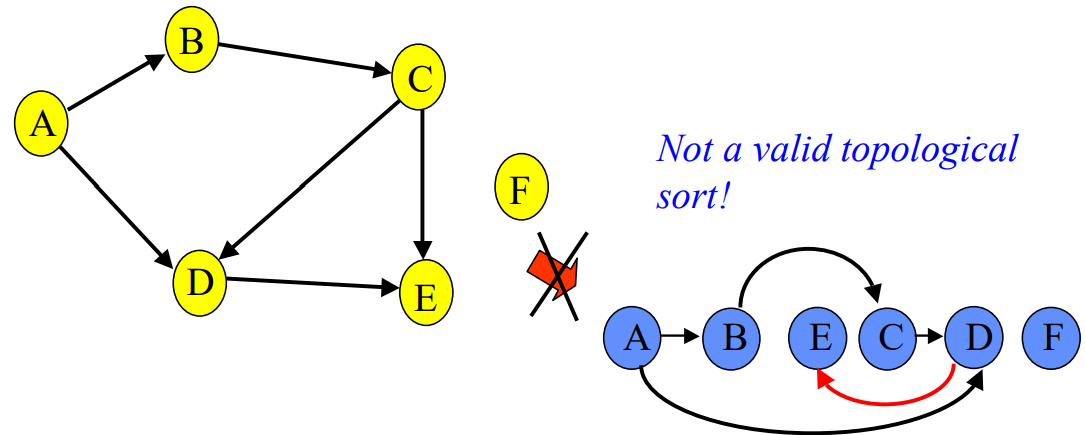
Below images are taken from Washington University Professor Rao’s CSE 326 Lecture 20. The problem is similar, except names of cities have become course numbers. We want to write down the list of course in their dependency order.
The following is not a topological sort.
For every directed edge \((u, v)\) from vertex \(u\) to vertex \(v\), \(u\) comes before \(v\) in the ordering.
The only type of graph that can have topological orderings is DAG. DAGs have no cycles. An equal couple cannot be topologically sorted. Only parent-children can be topologically sorted.
Topological sort can be done by DFS or BFS. Khan’s algorithm is BFS.
DFS
In DFS we talked about topological sort and how it is just like DFS. In DFS, each node at the top is not finished until its dependents are finished.
A topological ordering will be the following:
New York, LA, London, Hong Kong, Beijing.
My solution seems to resemble Khan’s algorithm for topological sort: solving problem layer by layer: start from those that have no dependencies (no incoming edges), remove them and write them down (put them in a queue). Do it to the next batch.
We use the dfs code see (source) below for topological sort.
from collections import deque
GRAY, BLACK = 0, 1
def topological(graph):
order, enter, state = deque(), set(graph), {}
def dfs(node):
state[node] = GRAY
for k in graph.get(node, ()):
sk = state.get(k, None)
if sk == GRAY: raise ValueError("cycle")
if sk == BLACK: continue
enter.discard(k)
dfs(k)
order.appendleft(node)
state[node] = BLACK
while enter: dfs(enter.pop())
return order
# check how it works
graph0 = {'D': ['C', 'B'], 'C': ['A'], 'B': ['A'], 'A': []}
print(topological(graph0))
def dfs(G, startNode,visited):
# initial value
if startNode not in visited:
visited.append(startNode)
# recurse
for node in G[startNode]:
if node not in visited:
dfs(G, node, visited)
return visited
g = {'A': ['B', 'D'],
'B': ['C'],
'C': ['D', 'E'],
'D': ['E'],
'E': [],
'F': []}
print(dfs(g, 'A', [], 5))
# ['A', 'B', 'C', 'D', 'E']
Time complexity
Topological sort can be done with \(O(V+E)\) time complexity.
Khan’s algorithm
Khan’s algorithm was invented by Arthur Kahn (1962). It is BFS and works by using a metric called “in-degree”, which is the number of incoming edges.
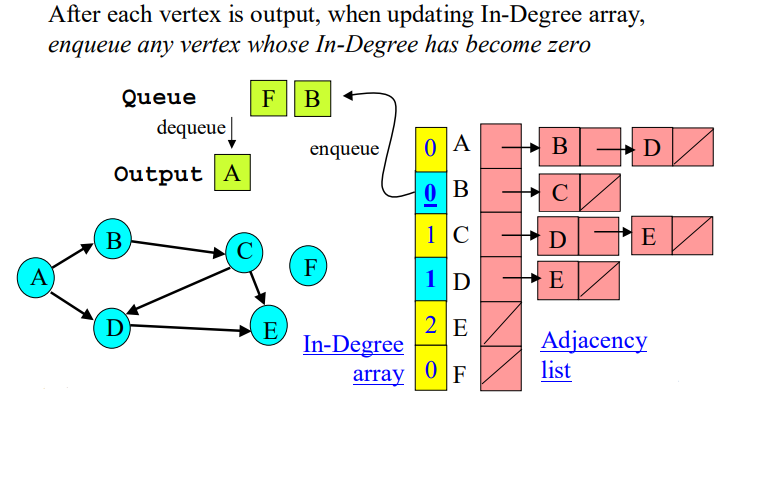
Step 1: Compute In-degree: First we create a lookup for the in-degrees of every node.
Step 2: Keep track of all nodes with in-degree of zero: If a node has an in-degree of zero then we can remove it since none else depends on it. At any step of Khan’s algorithm, if a node is in q then it is guaranteed that it’s “safe to remove” because it does not depend on any node that “we have not taken yet”.
Step 3: Delete node and edges, then repeat: We take one of these special safe courses x from the queue q and conceptually treat everything as if we have deleted the node x and all its outgoing edges from the graph g. In practice, we don’t need to update the graph g, for Khan’s algorithm it is sufficient to just update the in-degree value of its neighbours to reflect that this node no longer exists. This step is basically as if a person took and passed the exam for course x, and now we want to update the other courses dependencies to show that they don’t need to worry about x anymore.
Step 4: Repeat: When we removing these edges from x, we are decreasing the in-degree of x’s neighbours; this can introduce more nodes with an in-degree of zero. During this step, if any more nodes have their in-degree become zero then they are added to q. We repeat step 3 to process these nodes. Each time we remove a node from q we add it to the final topological sort list result.
from collections import deque
from networkx.generators import directed
from networkx.generators import random_graphs
# Make good adjacency list for testing (is DAG)
g = directed.gn_graph(100)
adj_list = g.adjacency_list()
# Make bad adjacency list for testing (is not DAG)
bad_g = random_graphs.fast_gnp_random_graph(100, 0.2, directed=True)
bad_adj_list = bad_g.adjacency_list()
from collections import deque
from networkx.generators import directed
from networkx.generators import random_graphs
# Make good adjacency list for testing (is DAG)
g = directed.gn_graph(100)
adj_list = g.adjacency_list()
# Make bad adjacency list for testing (is not DAG)
bad_g = random_graphs.fast_gnp_random_graph(100, 0.2, directed=True)
bad_adj_list = bad_g.adjacency_list()
def topsort(adj_list):
def edges(): # Returns list of edges
return [val for subl in adj_list for val in subl]
def no_incoming(): # Generates set of all nodes with no incoming edges
return set(range(0, len(adj_list))) - set(edges())
L = [] # L <- Empty list that will contain the sorted elements
S = deque( no_incoming() ) # S <- Set of all nodes with no incoming edges
while len(S) > 0: # while S is non-empty do
n = S.pop() # remove a node n from S
L.append(n) # insert n into L
for m in adj_list[n]: # for each node m with an edge e from n to m do
adj_list[n].remove(m) # remove edge e from the graph
if m in no_incoming(): # if m has no other incoming edges then
S.append(m) # insert m into S
if len(edges()) > 0: # if graph has edges then
raise Exception("Not DAG") # return error (graph has at least one cycle)
else: # else
return L # return L (a topologically sorted order)
DFS vs. Khan’s for topological sort
I got the answer from SOF: Kahn’s algorithm and DFS are both used to topological sorting in practice. Which to choose depends on your graph and its representation:
If you don’t have easy access to the list of all vertices (like when you only get a reference to the root of the graph), then would have to do a search to find them all before implementing Kahn’s algorithm, so you might as well use DFS and do your topological sort at the same time.
If your graph might have a long path, then it would be inappropriate to use a recursive search. A DFS implementation should use an explicit stack, and that makes it more complicated than Kahn’s algorithm. If you do have a list of all vertices, then you probably want to use Kahn’s algorithm instead.
Cycle detection
A complete topological ordering is possible if and only if the graph has no directed cycles, that is, if it is a directed acyclic graph.
Khan’s algorithm of topological sort can be used for cycle detection.
If there is a cycle in the graph then result will not include all the nodes in the graph, result will return only some of the nodes. To check if there is a cycle, you just need to check whether the length of result is equal to the number of nodes in the graph, n.
Why does this work?: Suppose there is a cycle in the graph: x1 -> x2 -> … -> xn -> x1, then none of these nodes will appear in the list because their in-degree will not reach 0 during Khan’s algorithm. Each node xi in the cycle can’t be put into the queue q because there is always some other predecessor node x_(i-1) with an edge going from x_(i-1) to xi preventing this from happening.
Compare with Floyd’s algorithm for topological sort
Appendix
Code for plotting the directed group. If we want undirected graph, use nx.Graph() instead.
import networkx as nx
import matplotlib.pyplot as plt
G = nx.DiGraph()
G.add_edge(0, 1)
G.add_edge(0, 2)
G.add_edge(1, 3)
G.add_edge(1, 4)
G.add_edge(3, 4)
# explicitly set positions
pos = {0: (-4, 0), 2: (1, -2), 1: (3, 0), 3: (10, 0), 4: (12, -2)}
options = {
"font_size": 36,
"node_size": 3000,
"node_color": "white",
"edgecolors": "black",
"linewidths": 5,
"width": 5,
}
nx.draw_networkx(G, pos, **options)
# Set margins for the axes so that nodes aren't clipped
ax = plt.gca()
ax.margins(0.20)
plt.axis("off")
Below is the shorter version of the course schedule code in this post.
def canDo(numCourses, prerequisites) -> bool:
# numCourses: int, prerequisites: List[list[int]]
adjList = {i: [] for i in range(numCourses)}
for c, p in prerequisites:
adjList[c].append(p)
visiting = set()
def dfs(c):
if c in visiting:
return False # cannot do it
if adjList[c] == []:
return True
visiting.add(c)
for p in adjList[c]:
if not dfs(p):
return False
visiting.remove(c)
adjList[c] = []
return True
for c in range(numCourses):
if not dfs(c):
return False
return True
Know your library
graphlib.TopologicalSorter
The graphlib library, part of Python standard library since Python 3.9. It does not have a lot of functionality yet. But it can do topological sort with graphlib.TopologicalSorter and cycle detection when the sorting fails.

import graphlib
from graphlib import TopologicalSorter
graph = {"D": {"B", "C"}, "C": {"A"}, "B": {"A"}}
G = {k:list(v) for k,v in graph.items()}
G['A'] = []
G = defaultdict(list)^M
...: for k, v in graph.items():^M
...: G[k].append(list(v))
dfs_res = dfs(G, 'D',[])
dfs_res.reverse()
dfs_res
# ['B', 'A', 'C', 'D']
# ['D', 'C', 'A', 'B']
# defaultdict(list, {'D': [['C', 'B']], 'C': [['A']], 'B': [['A']]})
ts = TopologicalSorter(graph)
tuple(ts.static_order())
# ('A', 'C', 'B', 'D')
H = nx.DiGraph(graph) # create a Graph dict mapping nodes to nbrs
print(list(H.edges()))
nx.draw(H, with_labels=True, font_weight='bold')
plt.show()
graph ={
'A': ['B', 'C'],
'B': ['D', 'E', 'F'],
'C': ['G'],
'D': [],
'E': [],
'F': ['H'],
'G': ['I'],
'H': [],
'G': []
}
ts = TopologicalSorter(graph)
print(tuple(ts.static_order()))
# ('D', 'E', 'G', 'H', 'C', 'F', 'B', 'A')
[1,0],[0,1]
course = {1: {0}, 0: {1}}
ts = TopologicalSorter(course)
print(tuple(ts.static_order()))
# CycleError: ('nodes are in a cycle', [1, 0, 1])
networkX
Reference
Washington University CSE 326 Lecture 20: Topo-Sort and Dijkstra’s Greedy Idea